I am an AI researcher working on LLM post-training & evaluation at Amazon AGI. Before Amazon AGI, I did research on aligning & evaluating LLMs for end-to-end generative AI based Customer Support Agents at ASAPP Inc from 2022-2024.
Even prior, I journeyed through my PhD from 2016-2022 with the
Language Technologies Institute, School of Computer Science
at CMU,
where I was advised by Prof. Eduard Hovy. My research is broadly on language generation, with specific interests in style transfer, data-to-text generation, narrative generation and low-resource & creative generation.
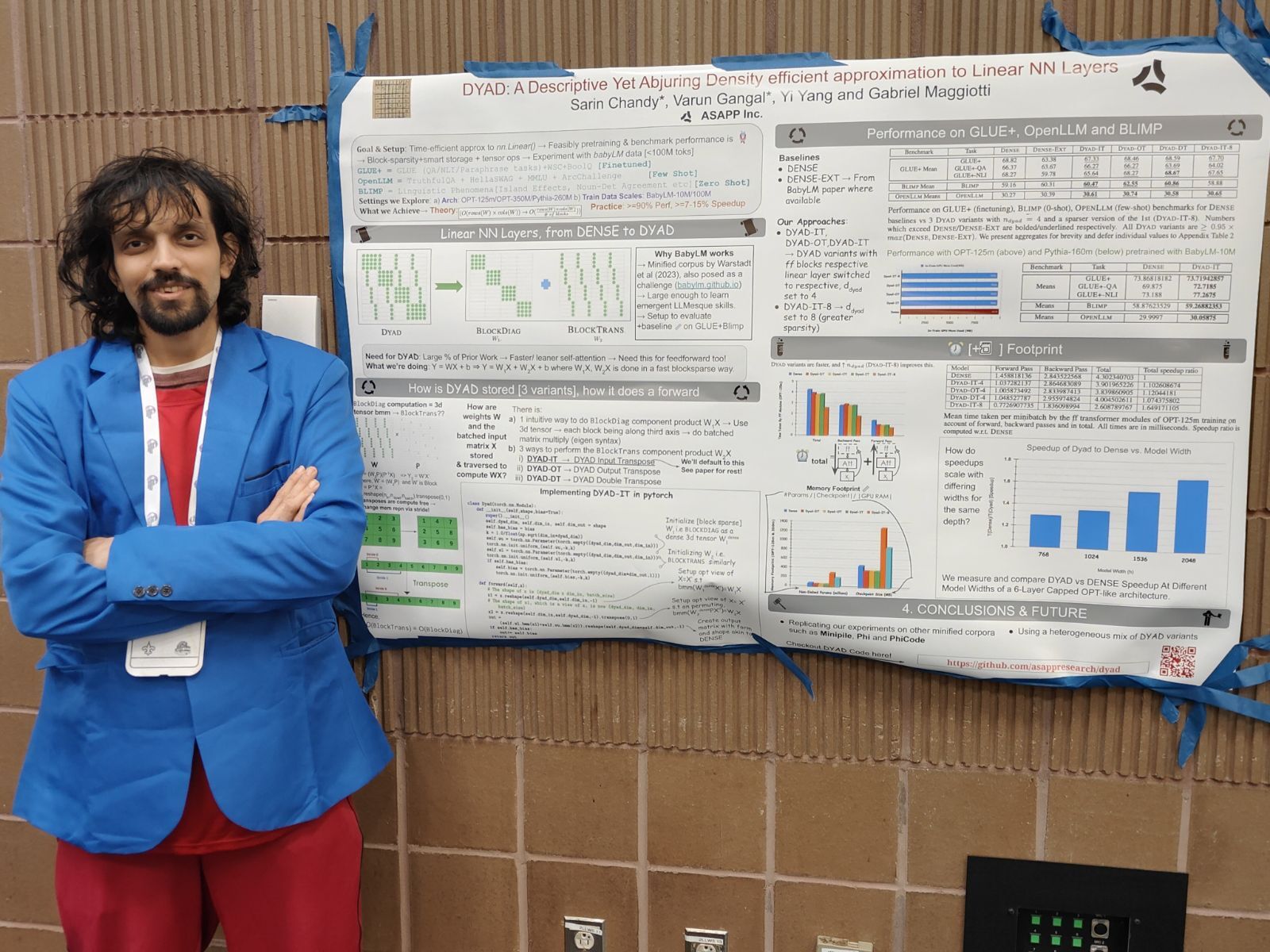
At NEURIPS 2023, New Orleans, at the WANT workshop, presenting my work on DYAD - a blocksparse, GPU-aware approximation to the MLP Layer. ⟶
In the past few years, I have also been involved in co-organizing many collaborative NLP research efforts, such as:
The GEM benchmark, associated workshop@ACL'21, and paper for better and standardized evaluation and comparison of NLG models and systems - a parallel to GLUE for generation
The challenge sets submodule of GEM, where we built domain-shifted sets under a unified theme for NLG tasks in our benchmark, using various perturbation [backtranslation], sub-selection [length] and other domain shift [diachronic] strategies. Our work was accepted @
NEURIPS'21 Datasets & Benchmarks Track!
The NL-Augmenter participative repository and benchmark, which provides a structure for NLPers to contribute and evaluate task-specific data augmentations a.k.a transformations, as well as subset selection strategies a.k.a filters. We aim to create a large, usable suite (~140 and counting!) of transformations and filters leveraging wisdom-of-the-crowd - opening the door to more systematic analysis and deployment of data augmentation/robustness evaluation.